Monat: Juli 2020
bookmark_borderOpen Source-Code im (noch) ewigen Eis
Die Online-Platform GitHub hat die verfügbaren (öffentlichen) Open Source-Projekte auf Mikrofilm verewigt und in Spitzbergen eingelagert, wo sich etwa auch das Global Seed Vault befindet. Neben den Codes selber sind auch einige grundlegende Techniken beschrieben. Größtes Risiko dürfte derzeit der Klimawandel sein.
Berichte bei heise Online, Spiegel Online
bookmark_borderplan3t.info jetzt pl4net.info
Der Blog-Aggregator plan3t.info, der Blogs aus der Bibliosphäre zusammenfasst, ist jetzt mit neuem Design unter neuer Adresse erreichbar: pl4net.info
Zu den Hintergründen gibt es einen kurzen Beitrag im „planeteneigenen“ Blog.
bookmark_borderAufzeichnungen der #OERcamp-Webtalks online
Bei den #OERcamp-Webtalks (Online-Vorträge zu OER) sind einige interessangte Vorträge dabei, u.a.
- Ideen sammeln priorisieren und weiternutzen mit Flinga und Etherpads
- Tutorials (oder interaktive Geschichten) erstellen mit Twine
Außerde gibt es eine Reihe von Videos zur Recherche nach frei nutzbaren Medien, u.a.
Auch, wer Einführungen in die Herstellung von Audio- und Video-Tutorials sucht, wird in der Sammlung fündig. Eine vollständige Liste mit Links zum Download gibt es bei Jürgen Plininger.
bookmark_borderDigitale Sammlungen als statische Websites
Der Schockwellenreiter stellt den Collection-Builder vor, ein Tool zum Präsentieren von Sammlungen als statische Websites auf Basis von Jekyll vor.
bookmark_borderWarum CSV nicht wirklich ein geeignetes Format für die Langzeitarchivierung ist
bookmark_borderDatenspeicher der Vergangenheit und Zukunft
Der Wissenschaftscomic „Klar Soweit?“ der Helmholtz-Gesellschaft beschäftigt sich in der Folge #76 mit DNA als Speichertechnik, streift dabei aber auch das Problem „klassischer“ Speichermedien.
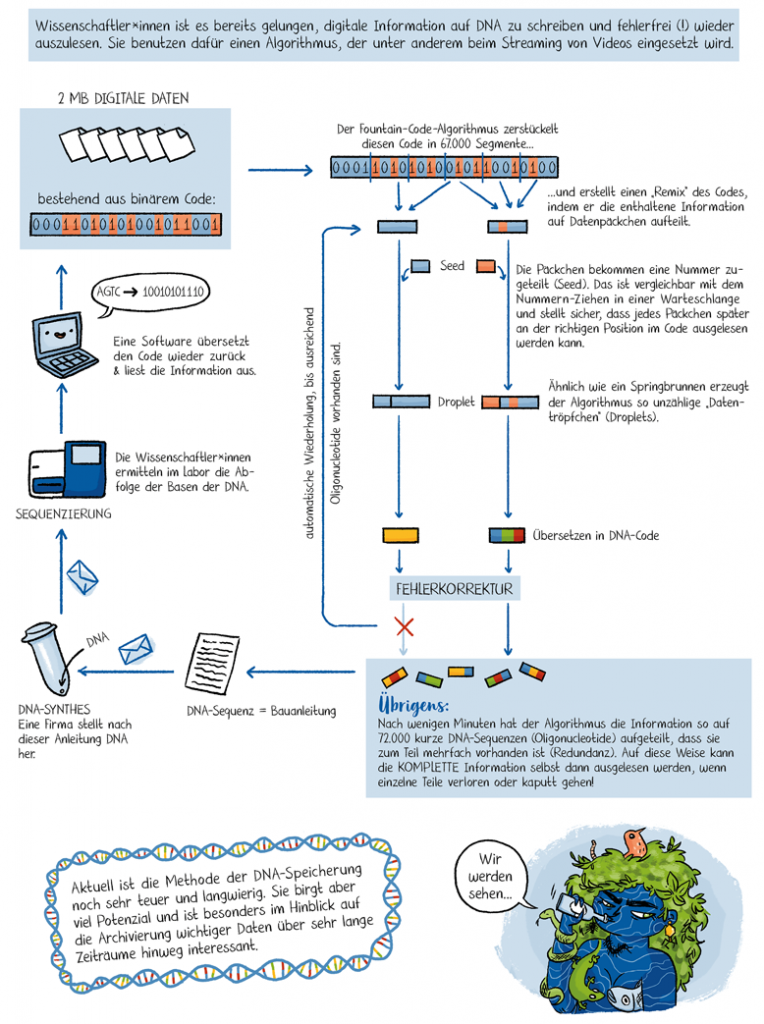
Im Blog der Helmholtz-Gesellschaft mit einleitendem Text und weiterführenden Links
bookmark_borderNeue digitale Veröffentlichungsreihe des Landesarchivs BW zu Fragen des Digitalen
Den Anfang macht „Digital ist besser? Möglichkeiten der automatisierten Aufbereitung und Bewertung von Fileablagen mit Python am Beispiel einer digitalen Fotosammlung“ von Stephan Lenartz.
Leider keine DOI, die einzelnen Hefte werden als PDF hier veröffentlicht.
Ich hatte das Problem, dass der heruntergeladenen Datei das Sufix fehlte – einfach Datei umbenennen und .pdf hinzufügen reicht aber aus.